Git gud
Introduction
I have earlier written a short piece on git, now I thought I’d take a moment to write a short description about the methodology I prefer to use in projects, a methodology that I find quite easy and useful. It’s in some parts based on the standard git-flow, but a lot of people I work with feel that flow is too complicated and I somewhat feel the same, especially in smaller teams. Flow is great, really, I like it, and I think that if you have a big team with seasoned developers, git flow is a great methodology to follow. But in a small team, especially if it includes junior developers or developers whom are not that used to git, a simpler methodology is probably preferred.
My intention is to use a simpler methodology which can later on move over to a more standard flow variant, making the move over easier for everyone. When I started thinking about this, I wanted something as easily managed as git flow but simpler, easier to understand, even for people who haven’t worked much with git before.
Development
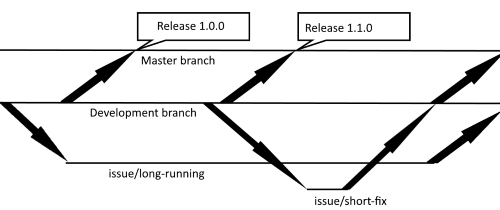
The master branch is the production branch. It should always be clean and what is in the master branch should always reflect anything in the production environment. So when working, the development branch will be the one that the developers work against. If a bugfix has to be added to the production branch, it should first be added to the development branch and then cherry picked (or merged if it’s time for a new release) to the master branch.
So when a new git repository is created, there should be two branches created:
> git clone <url>
> git branch develop
> git push origin develop
> git branch
* master
* develop
Now both the remote and the local repos have the main branches created.
Branches
Git is awesome when it comes to branches. Creating a new branch is (in contrast to SVN) a piece of cake. So when working against a repository where there are more than one person working, branching is almost a must.
I often use the git-flow naming convention for my branches (feature/<id>-description), but a preffered naming in this case would be issue/<id>-description, due to it not only being features, but rather issues.
When a new issue is being worked on, it should always be connected to a issue in the issue tracker - Yes, a good issue tracker is almoast required for this to work! If there is no issue for the task, one must be created.
Most issue trackers are possible to connect directly to the git repository, making any commit messages connected to a issue show up in the issue log, this is great, and I use it a lot in my workflow, but this is of course not a must, but rather a thing that is quite nice to have.
So when creating a new branch, locate the issue and get it’s reference number (or how the tracker now references issues) and name the branch accordingly:
git branch issue/123-short-description-of-issue
git checkout issue/123-short-description-of-issue
It’s important to not create to big issues, a issue should be a small thing, and the branch should only contain the changes that the issue reflects. If you start working on other stuff in the same branch you are doing it wrong. That means, if you decide that a tiny refactoring - in the code - would be nice while you are working on the issue, don’t start doing it right away, add a new issue and take care of it later.
In a “real” flow repository, the branches are named depending on what the issues are, a feature is prefixed with feature/, a hotfix with /hotfix, releases have their own branches and they are prefixed with release/. To make the whole thing simpler, I prefer to use one prefix for all, issue/. A hotfix/bugfix is also a issue, while the release suffix is skipped all together and instead tags are used to mark deploys directly in the master branch.
Comments
When working, commit often. It’s okay to have a lot of commits in a single check-in, in worst case, you might want to squash the commits into a single (or a few) bigger ones, but this is less important in my opinion, rather have a lot of smaller commits so that the workflow is documented in git and so that any reviewer can see what have been done and in which order. But the most important thing when it comes to commits is to write good messages.
If you write good messages, the reviewer will have a much easier job knowing what it is you have done and why, don’t just write added file x.php, Fix or blaaahh, write a short description about what you did. The first 60 or so characters in the message can be a mini summary of the commit and then you can add more information on the lines after that.
Keeping a neat and well documented git repository is really important.
Issue done
When a issue is completed it should be added to the development branch. This should not be done right away, everything should be tested and reviewed before adding it to the development branch. Having a well tested and controlled dev branch makes releases a whole lot more easy!
Push the branch to the repository. If you wish, it is okay to rebase it before pushing, but not after. If you have pushed a branch to the repository once and keep on working, don’t rebase, it will make the history odd and might confuse the reviewer.
When you have pushed the branch, create a pull/merge -request. This is almost always a easy task in any git remote web interface, but it might vary, so I’ll not write about that here.
Pushing your branch is easily done with the following command:
git push origin issue/<my-branch>
When creating a pull/merge -request, it’s even more important to write a message wich contains a summary of the changes. Communication is really important, and everything should be as documented as possible to make it easy for everyone in the team (or outside in some cases) to keep track of what is happening - without having to go to the issue tracker (or in worst case the documentation or something!).
Review and merge
When a issue branch has been pushed someone (not the same person as the one whom pushed the branch) should review the code. Hopefully your CI setup builds and tests the code on issue branches, else it will have to be done by the reviewer. Reviewing code can be done in most remote web interfaces, if it can’t, it can be done locally, most decent IDE’s or code editors have some type of history when it comes to git, making it a lot easier to see what have been changed and when. The git log and diff tool can be used else, but that can be a bit more messy.
Just read the code, make sure that no obvious bugs or errors and always make sure that the issue it is supposed to resolve is actually resolved. Comment when something is found in the code that is odd or you find a bug, comment if you find something that you find nice or cool, positivism makes people happy and everyone likes to hear when they have done something good! If you have to deny a request, make sure that you explain why. In my personal opinion, if a request have to be denied due to it not implementing the needed changes, it’s extremly important to look at the issue description and make sure that it’s clear enough. If issues are difuse, missunderstandings are common.
When a branch has been reviewed - and it’s okay to merge - it should be accepted. It’s always good to write a comment even there, something encouraging or just a “LGTM” comment is really enough, but leave a comment. Then merge the branch into the development branch.
The development branch is not as “sacred” as the master branch, but it should always be possible to build. I often use the development branch as the staging branch, automatically deploying all code in dev to the stage environment. If that is done, its quite important that the code builds!
Releases
Releasing features should be done quite often. Try stick to a continuous integration kind of method, where the dev branch often is merged into the master branch and releases are done often. Especially in web projects, maybe not as often for application projects (as those often have a deployment process including acceptance from a third part). Personally I prefer to have this stuff automatic, if you can keep the dev branch stable enough and the people reviewing and accepting requests know what they do, make the merges automatic, else just do manually. Tag each new release with a version number, so you know when and where a deploy was made, and let the CI environment do the actual deployment. Removing any human interaction from the deployment is a good thing, that makes failures due to human errors a lot less frequent!
Repo master
It’s always good to have one person in charge of the master branch, protect it and let only the person in control merge stuff into it. The person whom deploys should probably also review any merge requests from the develop to the master branch, that way there will be a proxy which makes sure that the code is clean and good. The person should probably be quite senior and should have a good understanding of the whole project, but the role is only useful if the project needs it.
It’s not always fun to be the person who have to review most of the code, but it’s good to have a last check before deployment.
Other tips
Developers should only focus on their own branches. If a issue is blocked by another issue, the branches should not be merged in to eachother but the developer should rather work on something else till the block is completed and merged into the development branch, then merge development branch into the issue branch and keep on going.
It’s okay to merge the development branch into the issue branches, but it’s not always necessary. If the developer is less used to handling merge issues, I personally prefer to see that the person in charge of reviewing and accepting the code takes care of it. And remember, it’s ALWAYS okay to ask for help. If you work in an environment where this is not okay, you should look for a new job. A team should be a team, not a group of people working for their own means only.
Summary
To summaries this in a shorter text:
- Each developer work in their own branches.
- Each branch is connected to a issue.
- A issue which is short and descriptive so that the branch don’t have to contain to much changes.
- When a issue is done, it’s pushed to the remote using the same name as it was called locally.
- After push, a pull/merge -request is created to the development branch.
- Here a reviewer takes over and inspects the changes.
- After review it is merged with the develop branch and a few lines of comments is added to the request before accepting/merging.
- When it’s time for a release, the repo master merges the develop branch into the master branch, which is built and deployed.
- A new tag is added with a new version.
That’s it.
And here comes a crude obligatory image that is intended to show the flow using arrows and stuff!